
What We Gain And Lose By Using Algorithms In Healthcare
Algorithms are becoming more common in healthcare. In the majority of cases, these algorithms achieve better diagnostic accuracy or treatment efficacy than the doctor. The reason for the rise of such algorithms is largely due to the parallel rise of big data. Along with these trends come questions about societal norms on knowledge, trust, and accountability. I will both ask and answer these questions.
Question 1: How Do Algorithms Change Our Perspective On What We Know?
For decades we have used the Evidence-Based Medicine (EBM) hierarchy to denote which research we think is good and objective. At the top, we have Random Controlled Trials (RCTs), meta-analyses mostly outlining RCTs, and guidelines written based on mostly RCTs. RCTs use controlled intervention to test a new treatment, whereas cohort studies use observation of real-world data. We think of intervention as more reliable because the researcher has the power to control the environment. Therefore, RCTs are the golden standard in modern medicine.
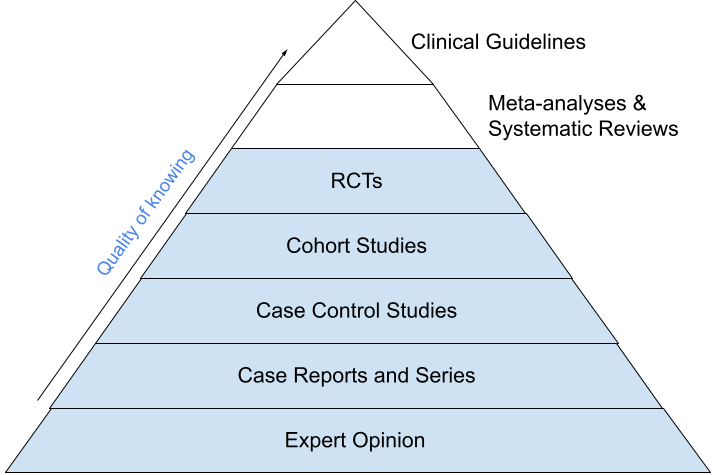
The EBM hierarchy
The dominance of RCTs is contested by big data. Studies tend to use big data from large groups, which is secondarily collected in the real world. RCTs, on the other hand, use controlled and randomized groups.
Breaking down the dominance of RCTs allows researchers to ask more innovative questions that otherwise would be infeasible or not even considered
Fundamental to the RCT approach is the concept of randomization. However, big data studies use randomization too, but in a different way. Where RCTs randomly assign persons to treatment or control groups, big data studies randomly define two real-world groups. One group is devoted to training the algorithm and one to validating the results. Both groups should be similar.

Difference in randomisation between RCTs and big data studies
Why This Matters
Randomization in RCTs should give us fewer cases of overestimation and fewer confounding factors (Stegenga, 2018). On the other hand, there are several problems with the RCT approach, such as studying in ideal circumstances, small sample sizes, and selection bias (Sanson-Fisher et al., 2007).
Looking at the pyramid, the dominance of RCTs also disincentivizes researchers to employ other designs. This becomes problematic given that RCTs are expensive and have short-term scopes. This is why these studies ask less innovative research questions (Sanson-Fisher et al., 2007). Beyond this, we can see how inherently RCTs withhold possibly effective treatment to a control group, while these people may actually benefit from treatment.
In this way, big data studies claim several advantages. These studies use real-world circumstances, have larger sample sizes, are able to increase observation lengths, and are less expensive since data is already available (Lee & Yoon, 2017). Such advantages already existed with cohort studies, but their impact has increased because big data is even bigger and less expensive.
Although selection bias is just as well a concern for big data studies, it is mitigated when data is drawn from multiple sources. This is simply more feasible with big data. Accordingly, breaking down the dominance of RCTs allows researchers to ask more innovative questions that otherwise would be infeasible or not even considered.
Tailored To You
One of these innovations is the rise of personalized medicine, where “The ethos of personalised medicine is that it rejects the supposedly one-size-fits-all or cookbook therapeutics of evidence-based medicine” (Solomon, 2016).
I will get into the structural reason why big data and algorithms allow us to enter a new paradigm; a paradigm that uses each individual’s characteristics responsible for treatment variation and, thus, allows us to move towards truly personalized medicine.
So far, personalized medicine studies have struggled to find effective tailored treatments because it mostly uses RCTs to prove causal links. However, disease progression, risk, and treatment efficacy are complex concepts. Hence, studying single factors is very ineffective (e.g. cancer; Cheng & Zhan, 2017).
Algorithms are not burdened by any requirement of understanding causal links. This allows for studying a multitude of factors simultaneously. Studying these multiple factors allows for personal treatment (e.g. someone can receive different treatment based on their genetic makeup or environmental factors). Making it more plausible to study millions of combinations, then, increases the window of opportunity to actually find something (Zhang et al., 2019). If treatment is successfully personalized, it becomes inherently more effective for that individual.
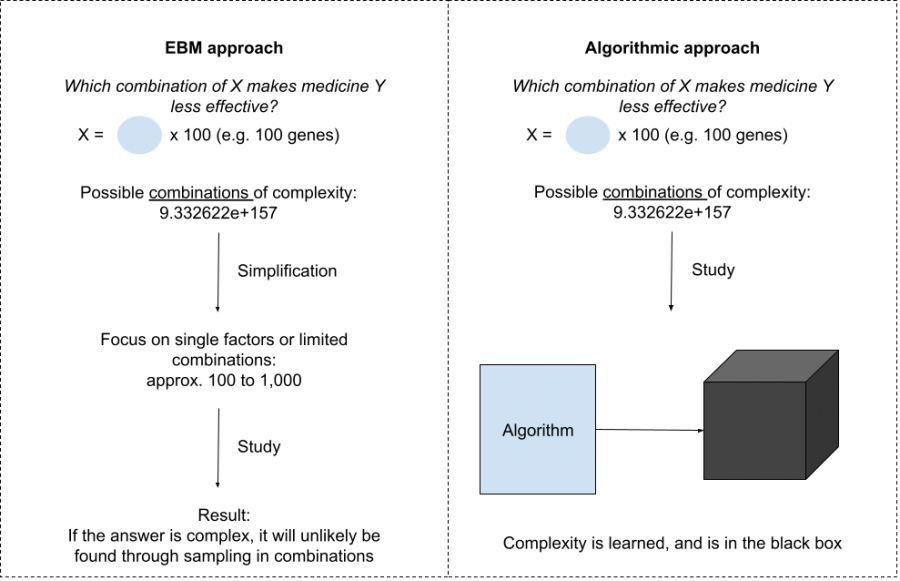
EBM vs algorithmic approach in personalised medicine
The problem, however, is that the solution is no longer out there, but folded in the black box. Two questions become relevant at this point:
- Do we need to understand what is in the black box?
- Are we able to understand what is in the black box?
This switches our discussion away from the big promise of personalized medicine. If there is an apparent question regarding its explainability, this would undermine the reasons we use algorithms to begin with (i.e. to treat patients).
Question 2: Why Don’t We Just Trust The Black Box?
This question sounds more obvious than it actually is. However, you should remember that we are required to trust something as knowledge. For centuries, society has used numbers as knowledge. Porter (1995) even claims the rise of trust in numbers runs parallel to the birth of nation-states and democracy. Numbers have authority because they are seen as objective, unbiased, and fair. I would say this is largely due to the self-explanatory nature of numbers for two reasons:
- The need for self-explanatory facts is one of the core values of a democracy
- Making decisions based on numbers shifts the responsibility for that decision to these numbers
This self-explanation characteristic is, therefore, necessary if we think about shifting this trust in numbers towards trust in algorithms. The black box characteristic of algorithms has a clear disadvantage in achieving this.
Even if you have the true explanation this does not ensure fair decision-making
Why We Call It A Black Box
Algorithms are basically mathematical tricks to find the best answer and create a model of the problem. The most popular trick is the use of Artificial Neural Networks (ANNs). An ANN does not calculate an answer directly but uses intermediate answers to increase complexity and flexibility. In this way, it can simulate real-world complexity better. These intermediate answers carry no decomposable meaning and are learned by the algorithm itself. This makes an ANN non-transparent (i.e. a black box).
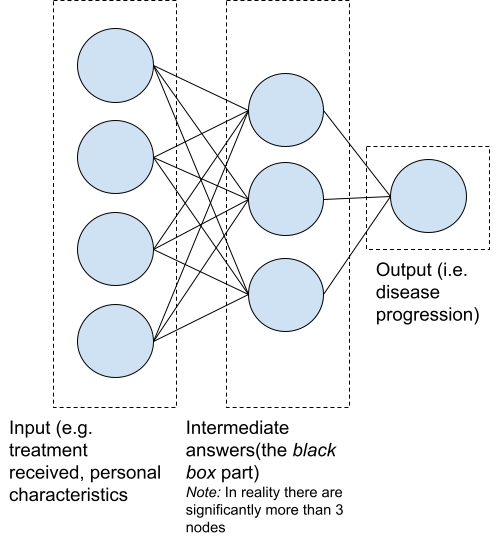
Example of an ANN (feedforward architecture)
Several strategies attempt to provide explanations for the algorithm’s answers. We call these eXplainable Artificial Intelligence strategies. Most of these strategies use surrogates (simpler replacements) to explain the algorithm’s answers. Even though these strategies give an answer, they don’t give us the real reasoning behind an algorithm and its understanding (Lipton, 2018). Thus, trust can not be earned through algorithms giving us self-explanatory facts, in the same way as numbers.
Back To The Question: Why Don’t We Just Trust The Black Box?
Given that a true explanation cannot be provided, we may turn back to our previous question: Why do we need to understand it? A central reason for this is that the stakes are high. Medical practice often has huge impacts on human lives. Solely and blindly relying on algorithms is not acceptable (Kim, 2015, pp.17-18).
The truth is that these models will make mistakes, leaving patients harmed. [..] When harm is done there is nobody to explain, reflect or be accountable for it
My response to this would be a question: Does the true explanation lead to full understanding? I would argue this is not the case. Even if you have the true explanation this does not ensure fair decision-making. Especially with transparent algorithms, we have seen many examples of faulty decision-making, discrimination on non-desirable factors, or disfavoured groups. For instance, predictive policing algorithms only use ZIP codes but still racially profile because ZIP code and race are correlated (Richardson et al., 2019).
The reason this happens is again: complexity. Data that includes bias will be reflected in both statistics and algorithms. I think that if full understanding is necessary for trust, then neither numbers nor algorithms are worthy of it.
Is Truth Really Necessary For Trust?
A skeptical person may wonder: If we were able to trust numbers even if they can be misleading, then why can’t we do the same with algorithms? I would agree. The amount of trust is not earned by fairness but by low perceived risk. In this case, this is mostly altered through experience with the algorithm or explainability (Hengstler et al., 2016). This brings us back to the need for explainability, even though it does not increase the truth or fairness of an algorithm.
In the same way as numbers, algorithms could gain authority by portraying them as objective. This plays with the theory of how trust in society is earned. Research shows how algorithmic limitations are often downplayed and how society shapes alternative truths on which trust can be built (Elish & boyd, 2018).
If full understanding is necessary for trust, then neither numbers nor algorithms are worthy of it
What We Are Left With
So, should we do that? If a model outperforms a clinician, this means less harm is done to fewer people. This is a net positive, even more so because doctors are not always good explainers themselves.
However, we are left with a more fundamental point: accountability. The truth is that these models will make mistakes, leaving patients harmed. Moreover, when harm is done there is nobody to explain, reflect or be accountable for the harm. This is exactly why currently there are few advocates for shifting the accountability on algorithms (Smith, 2021). It remains with the human doctor.
Question 3: Does The Algorithm Itself At Least Understand The Solution It Gives?
There is more to say about the difference between numbers and algorithms. Where numbers reflect the world, algorithms model it. Therefore the algorithm attempts to understand. However, algorithms change the concept of what it means to understand.
Traditionally we thought, understanding requires capturing the meaning of something. This meaning is grounded in embodied symbols; I know something is an object because I feel, see, smell, hear, or taste it and, therefore, know what it means. Algorithms are incapable of this since they are not embodied but simply recommend based on prior thoughts of contributors to its data. It does not understand the problem and solution. It doesn’t even know that it is an algorithm (Luger, 2021, pp. 116). Implementing these algorithms creates a situation in which neither the doctor nor the algorithm understands anything.
We may wonder if this is desirable; if understanding is necessary for knowledge or if knowledge can be something that a model tells us. I believe the latter would be hard to argue.
Question 4: Where Do We Go From Here?
In this article, I answered three questions that are fundamental to the production of knowledge through algorithms. So far, we have seen that algorithms enable more opportunities in medicine by contesting the dominance of RCTs in science and moving toward personalized medicine.
On the other hand, I attempted an answer on trust, accountability, and understanding. As you may have noticed, I have given insufficient answers (respectively: a sociological answer, referring to a lack of advocates and stating that I thought it was hard to argue).
This may leave you unsatisfied, but the truth is that I am unsatisfied too. Since many believe we are at the start of a breakthrough, it is worrying that there are no answers to the questions this article leaves. That means that we have work to do.
Implementing these algorithms creates a situation where neither the doctor nor the algorithm understands anything.
References
Cheng, T., & Zhan, X. (2017). Pattern recognition for predictive, preventive, and personalized medicine in cancer. EPMA Journal, 8, 51–60.
Elish, M. C., & boyd, dannah. (2018). Situating methods in the magic of Big Data and AI. Communication Monographs, 85(1), 57–80.
Hengstler, M., Enkel, E., & Duelli, S. (2016). Applied artificial intelligence and trust-The case of autonomous vehicles and medical assistance devices. Technological Forecasting and Social Change, 105, 105–120.
Lee, C. H., & Yoon, H. J. (2017). Medical big data: Promise and challenges. Kidney Research and Clinical Practice, 36, 3–11.
Lipton, Z. C. (2018). The Mythos of Model Interpretability. Queue, 16(3), 31–57.
Luger, G. F. (2021). Knowing our World: An Artificial Intelligence Perspective (1st ed.). Springer.
Porter, T. M. (1995). The Political Philosophy of Quantification. In Trust in Numbers: The pursuit of objectivity in science and public life (pp. 73–84). Princeton University Press.
Richardson, R., Schultz, J. M., & Crawford, K. (2019). Dirty Data, Bad Predictions: How Civil Rights Violations Impact Police Data, Predictive Policing Systems, and Justice. New York University Law Review, 94(192), 192–233.
Sanson-Fisher, R. W., Bonevski, B., Green, L. W., & D’Este, C. (2007). Limitations of the Randomized Controlled Trial in Evaluating Population-Based Health Interventions. American Journal of Preventive Medicine, 33(2), 155–161.
Smith, H. (2021). Clinical AI: opacity, accountability, responsibility and liability. AI and Society, 36, 535–545.
Solomon, M. (2016). Medicine and society: On ways of knowing in medicine. Canadian Medical Association Journal, 188(4), 289–290.
Stegenga, J. (2018). Evidence in Medicine. In Care and Cure: An Introduction to the Philosophy of Medicine (pp. 103–124). The University of Chicago Press.
Zhang, S., Bamakan, S. M. H., Qu, Q., & Li, S. (2019). Learning for Personalized Medicine: A Comprehensive Review from a Deep Learning Perspective. IEEE Reviews in Biomedical Engineering, 12, 194–208.