The YouTube algorithm and its problems
The Youtube algorithm has been the subject of much criticism. The filter bubble (Sunstein, 2017) it creates and the fact that the algorithm just wants to keep the viewer watching, with no regard for societal and personal needs come to mind (Van Dijck, 2013).
Recently this has been connected to the discourse on conspiracy theories by the popular Dutch satirical news show Zondag met Lubach. All these issues are because of all three stages in AI’s procedure. The data that the algorithm gets fed is inherently wrong and the algorithm itself was made with mainly profit in mind. Furthermore, the interpretation cannot be properly executed I believe that these are the core issues with the Youtube algorithm. I will show all these things by analyzing the algorithm connected to YouTube in terms of the philosophical debate on algorithmic bias and injustice as a part of moral philosophy (Barocas, 2014).
Youtube Algorithm: Theory
To give a wider scope to this I will explain the different parts I will be analyzing. Often people criticize algorithms themselves. I wish to broaden this scope and look at the three stages where there can be issues. The first is the obvious algorithmic stage. This is the coding and algorithm itself. Here there can be bias because a human made these and thus the code can have various goals and biases. Secondly, there is the interpretation stage. The question here is how are the results interpreted and is that good? Can they be interpreted well or is there a black box or some other obstruction? Lastly one must also look at the data. Is it of high quality and representative of the population? Does it have implicit biases in collection labeling or categorization? This is the basis of all the other work and thus we must look at these as well (Barocas, 2014).
Interpretation
First of all, as I previously said the interpretation of the algorithm’s results is an issue. The results would in this case be the videos that the viewer sees. They can thus interpret these results by clicking on one of these videos. Inherently there is nothing wrong with this act. However, the algorithm is a sort of black box. It is impossible for most users to know what data and process the AI uses to generate their recommendations. The algorithm used is not public. Even if it were the viewer would not know what exact data is used to generate this feed. An average user does not understand their recommendations fully. Thus they can easily make bad decisions (Barocas, 2014).
This does not mean that in practicality all users would make rational decisions if they did know what YouTube's recommendations are based on. However, without this knowledge, it is impossible to do so. Thus, the black box is a disabling factor. Its absence would not be the sole enabling factor for rational decision-making.
Black Box
An average user does not understand their recommendations fully. Thus they can easily make bad decisions.
For instance, one could be recommended a conspiracy theorist video based on previous searching behavior. However, if you were merely watching similar videos because of research clicking them after the research is completed would not be useful. However, as a user cannot know that this is what informed the decision to show that particular video they might still do so. Thus as the user does not know why the video is recommended, they cannot properly interpret the recommendations (Barocas, 2014).
The Algorithm
Secondly, we must look at the algorithm itself. While we do not have access to the algorithm’s code we do know with what goal google made it. Their goal is for people to watch a lot of content that ads may run on. That is the way YouTube earns money. They sell these targeted ads(Van Dijck, 2013). Now one may say that this is not inherently wrong. However, it fails to take into account the effects of these recommendations on individuals and society, or substantive fairness. Algorithms like these have often been accused of forming a filter bubble or echo chamber. Such an algorithm can have adverse effects on society (Sunstein, 2017).
However as the algorithm has a different function, namely generating traffic, it does not take into consideration the negative effects that can be caused by its widespread usage. These include polarization and spreading false information among other things (Min et al, 2019). Due to YouTube's wide user base, such negative effects can impact a large portion of society. The negative press surrounding such an impact could be a motivating factor for YoutTube to change its policy.
Thus the algorithm itself is an issue as societal as substantive fairness is seemingly not a factor for it. The algorithm is not intended to create a result that is substantively fair. It may create the desired result of creating profit, but does not take societal/personal benefit into account. All that matters for the YouTube Algorithm is profits (Van Dijck, 2013; Barocas, 2014; Crawford, 2013; Gillespie, 2018).
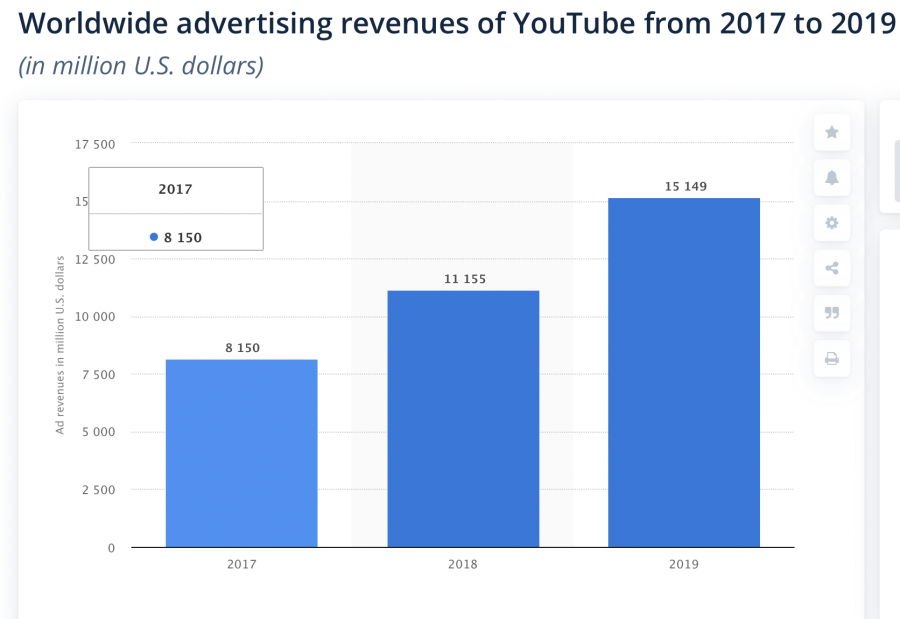
Statistics on YouTube's advertising revenue
Data
Lastly, the data that the AI uses is inherently biased. This is for multiple reasons. I decided to focus on two particular ones, however, this is not an extensive list.
Primarily, wealthy western people have more access to the internet and thus there will be more data on their behavior. The algorithms will thus make better judgments about their behavior than others. This is called a statistical bias. There are examples like this all over. Certain people will get better recommendations and thus there is inequality of quality recommendations.

Statistical information on internet usage
Thus the data used in the YouTube algorithm are wrong because their collection has a statistical bias and properly labeling them is difficult to impossible
Moreover, the labeling of the data could be an issue. It is rather difficult to know why a person watched a certain video. The fact that I watched a video on Qanon could mean I am a conspiracy theorist or that I am researching Qanon. Furthermore, if someone sent me a video as a joke and I happened to click on it, that makes this view less meaningful than when I go out of my way to search for a video. Youtube can thus not know whether to categorize it as a type of video I liked watching or not. The decisions that have to be made when categorizing data on youtube are very hard to make without asking the viewer. YouTube does not do this. There are some methods available such as referencing with other data, but these do still not provide insight into individuals' mental states. Sarcasm, trolling, researching, and genuine interest for instance are very hard to keep apart. Thus the data used in the YouTube algorithm are wrong because their collection has a statistical bias and properly labeling them is difficult to impossible (Van Dijck, 2013) (Crawford, 2013).
Conclusion
In sum, all parts where an AI could go wrong show issues with the YouTube algorithm. The collection and labeling of data are inaccurate and biased. This data then goes into an algorithm that has profit in mind over anything else. This thus can not give results that are societally and personally beneficial. It is not substantively fair. Lastly, it is really hard to properly interest the results or recommendations as the viewer does not know the exact data and prices the AI uses. This creates a black box that the user cannot access. This leads to faulty decisions on what video to watch.
Thus all three stages of the YouTube algorithm have issues. This is the conclusion I draw from analyzing the YouTube algorithm in terms of the philosophical debate on algorithmic injustice and bias.
References:
Crawford, K., (2013). The Hidden Biases in Big Data. Harvard Business Review. Description