
Algorithmic discourse analysis: the good and the bad of LDA topic modeling
For culture studies and sociolinguistics alike, discourse analysis is a great method to understand society. But in a post-digital world where online culture has become undeniably relevant, two things are happening: we are creating and disseminating discourse at a far higher volume and velocity, and we have the tools to analyze discourse at a far greater scale. One of those tools is computational discourse analysis. These algorithmic methods can be used to analyze hundreds, thousands, or even millions of pieces of discourse in a matter of minutes. But is more always better?
In this article, I will introduce you to one of those computational discourse analysis methods: LDA topic modeling (Blei, 2003). First, I will explain what LDA topic modeling is and I will show its (un)usefulness in a case study of my own research. Then, I will dissect the good, the bad, and the ugly about LDA topic modeling in discourse analysis. At the end of the article, you will find some useful pointers for those who want to try out LDA topic modeling for themselves.
What is LDA topic modeling?
LDA topic modeling is an algorithmic machine-learning approach to discourse analysis. It consists of building an algorithm that takes a collection of texts as input and looks for topics in these texts. It does so on the basis of Bayesian statistics (Blei, 2003). For my own research, I have looked into the statistical models and mathematical calculations underpinning LDA topic modeling. For a student of digital culture, this was scary. I mean, just look at this monster:
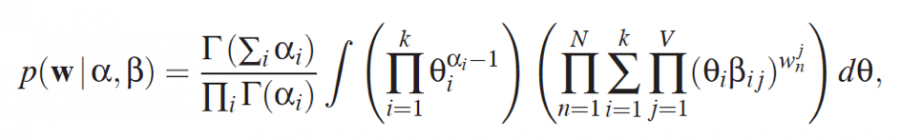
One of the calculations underpinning LDA Topic Modeling, taken from the original paper on Latent Dirichlet Allocation by Blei et al. (2003)
But don’t worry. In this article, I will spare you the trouble, since understanding these calculations is not essential for understanding or using LDA topic modeling. For those interested, I will share some essential resources at the end of this article. The important thing to keep in mind right now is that LDA topic modeling (and all other forms of machine learning) is not intelligent, conscious, or magical. It’s just statistics on steroids (Beerends in Van Trigt, 2023)
When we are building these statistical models to find topics in a collection of texts, we are making two important assumptions: 1) Every text contains one or more topics, and 2) These topics can be identified by looking for co-occurring keywords. An LDA topic model goes over all the texts we feed it and looks for words that have a high probability of being repeatedly used together. It then collects these words in a set of clusters – the topics. Once it has these clusters of keywords, it analyses every text individually to determine the degree to which certain topics occur in that text. This is a gross oversimplification. But for now, that is okay.
Let’s look at an example to make LDA topic modeling a bit more tangible. We could use this method to identify the themes in movies. If we feed an LDA algorithm a set of movie scripts and instruct it to create 10 topics, the algorithm will go over all the scripts and identify which 10 topics are in all the scripts combined. These topics are defined in the form of collections of keywords. These are the words that co-occur often enough for the algorithm to recognize them as semantically connected and thus constituting a topic. It then goes over each movie individually and gives us the percentages to which our topics are present in that movie.

How an LDA topic model assigns topics to texts
In this example, the first two topics that our algorithm has identified are [Bee, Honey, Hive, Fly, Insect, Black, Yellow, Sting, Queen] and [Sex, Pagan, Paganism, Religion, Cult, Offering, Ancient, Leader, Flower]. Let’s call the first topic ‘Bees’ and the second topic ‘Pagan sex cults’. If we look at the level of individual movies, we might find that the script for Bee Movie belongs to Topic 1 for 89% - makes sense. It also belongs to Topic 2 for 0,001% The Wicker Man, however, belongs to Topic 2 for 64%, since the movie is about a pagan sex cult. But it also belongs to Topic 1 for 4% - no doubt thanks to the classic ‘NOT THE BEES!’ scene in the movie.
Now the thing with a statistical model like our LDA model is that it is incredibly stupid. It actually does not know what we humans think of as a topic. It just looks for statistically often co-occurring keywords. Sometimes, this method results in topics that make total sense, like in the example above. But often enough, it results in clusters of words that might represent a ‘topic’ in the statistical sense of the word, but not in the sense that we are looking for. For example, in an analysis of 19th-century literature, Professor of English Ted Underwood (2012) found the cluster [love, life, soul, world, god, death, things, heart, men, man, us, earth]. This is too vague a collection of words to consider a proper topic. Underwood resolves this issue by interpreting this cluster not as a topic per se, but rather as a discourse. He writes:
“[LDA topics] are, technically, “kinds of language that tend to occur in the same discursive contexts.” But a “kind of language” may or may not really be a “topic.” I suspect you’re always going to get things […] which are better called a “register” or a “sociolect” than they are a “topic”.” (Underwood, 2012)
This makes it hard to interpret the topics that an LDA model puts out. Does the topic represent an actual theme? Or is it more about the ‘kind of language’ used? Or is our model just not good enough yet in identifying proper topics? In order to decode what an algorithmically identified topic actually represents, we always have to go back to the data and look at it as humans (Rhody, 2012). This human interpretation of the algorithmic topics is crucial when using LDA topic modeling in discourse analysis. In that sense, the topics are not only the result of all the choices we made in collecting, transforming, and analyzing the data with our LDA model (we’ll dive into this in a minute), but they are also the starting point of a new round of analysis. The model provides the topics, we provide the meaning.
A case study: how have I used LDA topic modeling?
You now know that LDA topic modeling is a machine-learning approach to discourse analysis that we can use to identify topics in a collection of texts. But why would you want that? Humans are arguably a lot better at recognizing topics than machines are. The main advantage is scale. I have used LDA topic modeling to analyze a set of over 155.000 tweets by influencers Ben Shapiro and Candace Owens. That is a volume of tweets I could never have analyzed manually in the timeframe of my research project. In this section, I will walk you through my research to show how you can use LDA topic modeling to analyze thousands of tweets.
Background information
First, a bit of background. The influencers I have investigated can be understood as right-wing metapolitical influencers. In their discourse, they give culture primacy over politics in an attempt to achieve (a conservative) cultural hegemony (Maly, 2018). This ideological project manifests itself in conservative discourses of race, gender, nationality, patriotism, and nostalgic atomic family values. Like all influencers, metapolitical influencers employ online media like Twitter to reach an audience and spread their discourse (Den Boer et al., 2023). Uptake is essential in their efforts. Not only because the online economy has marketized attention as the ultimate incentive to create and share content (Venturini, 2019), but also because the uptake of a message co-constructs the meaning of that message.
Some metapolitical influencers are so successful at generating uptake of their conservative content, they become important actors in the political and societal debate in the hybrid media system (e.g. Maly, 2020; Riedl et al., 2022). It can be interesting to understand what kind of topics these influencers deploy to gain attention and spread their metapolitical messages. Especially when the stakes are high, e.g. during an election period. Do they limit themselves to policy issues, or do they also talk about personal issues? Do they follow big cultural events, or do they set their own agenda? I used LDA topic modeling to investigate the discourse of Shapiro and Owens on Twitter during two weeks leading up to (and including) the 2022 US midterm elections in order to assess what the most popular topics in their discourse are and how they deploy these topics to generate interaction and influence on Twitter. And, since uptake is essential in co-constructing the meaning of their discourse, I also analyzed the reactions to their tweets in the same period.
Building an LDA model is all about making choices
For this project, I wrote my own algorithm in Python using the Gensim and spaCy libraries, but you can also write your algorithm in R or use more ready-to-go applications, like MALLET. I won’t bore you with programming mumbo-jumbo (again, relevant resources are mentioned at the end of this article). But I will walk you through the code that I wrote and the choices I made. Because building an LDA model is all about making choices. As I wrote at the start of this article, machine learning is not magic – it’s statistics. And we have to decide how we will build our statistical model.
Input data
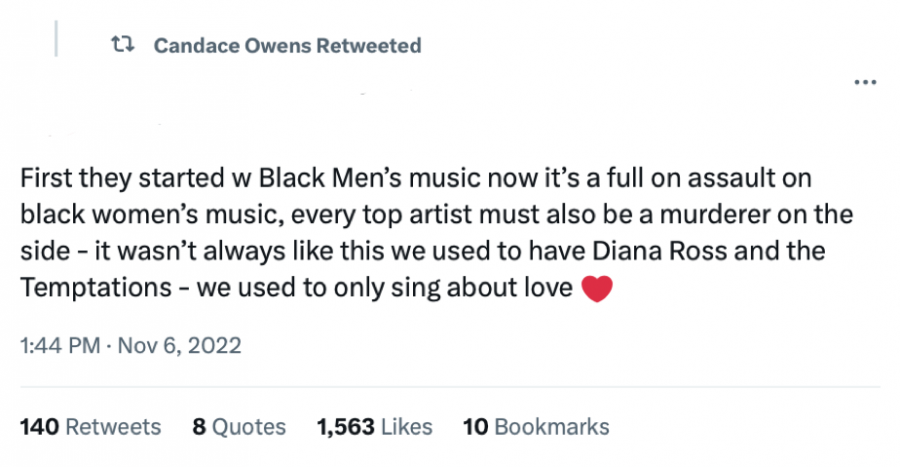
The first choice we have to make is what data we are going to use as input for our model. In this case, I chose to use Twitter data collected by Dr. Saif Shahin about Shapiro and Owens. The interesting thing about this data is that was collected in the weeks leading up to the 2022 USA midterm elections. This makes political topics even more explicit. I also chose to include the replies Shapiro and Owens received on their tweets in my data, since I was interested in how people responded to certain topics. The data was divided into four sub-sets (Shapiro posts, Shapiro replies, Owens posts, Owens replies) to allow the model to identify topics emblematic for each individual subset of the data – which I hoped would result in a more granulated understanding of the data. Let’s take one retweet by Candace Owens in the data and see how it changes as we prepare it for our algorithmic analysis. This is the original tweet:
Pre-processing
Once we have chosen the data we want to analyze, we need to pre-process the data. This step consists of many smaller steps which help to make the tweets interpretable to our model. First, we only take the lowercase text of the tweet to interpret. In doing so, we lose all other modes of communication like pictures, GIFs, typography, or uptake metrics. This is what our tweet looks like as plain text in Python:

Next, we delete interpunctions and stopwords like ‘and’, ‘but’, ‘in’, and ‘on’. These words in themselves are ambiguous and too commonly used to help us distinguish meaningful topics. We also remove the plain text hyperlinks from the data for the same reason. Also, we remove all instances of @realcandaceo from the Owens replies subset and @benshapiro from the Shapiro replies subset since every tweet in these subsets includes the handle of the influencer they are replying to. Finally, we delete some stylistic elements, like double spaces and blank lines.
The next step is to make ‘bigrams’ and ‘trigrams’. Basically, we tell our model to include groups of words that have a unique meaning when they are combined. E.g. ‘January’ and ‘Riots’ have their own independent meanings, but when they are combined with ‘6’ to make ‘January 6 Riots’, they refer to a specific historical event. And we want our algorithm to recognize such a set of words as one keyword. After these first pre-processing steps, our data is brought down to the following list of words:

The next step of pre-processing is to choose which ‘parts of speech’ (spaCy, n.d.) we want to include. In this case, I chose to only include (proper) nouns, adjectives, and numbers. Usually, you would also include verbs, but I found that without the verbs, we can avoid the ‘topics that are actually kinds of language’ that we talked about earlier. Of course, these kinds of language can be interesting – for example when we are interested in the tone of voice of the influencers. But in this case, we are only interested in the things they talk about, not in how they talk about them. With the types of speech decided upon, we also decide whether we want to lemmatize the words in our data. If we do, we bring all words back to their core. So ‘Home’, ‘Homes’, and ‘Homely’ all become ‘Home’. Bringing words back to their core makes it easier for the model to recognize which words are often used together. Our tweet now looks like this:

The final step is to turn the words into numbers. After all, we can only do statistics with numbers. So what do we do? We put all the lemmatized words we have left in a row and give every word two numbers. The first one corresponds to the place of the first occurrence of that word in the complete row of words, the second one corresponds to the number of times that word occurs in the tweet it is in. That way, each word has its own numerical representation that we can then feed into our model. As you can see, the data that we actually put in the model looks nothing like the original tweet we are analyzing:

Choosing the number of topics
One of the most important choices we have to make is how many topics we want to find. This is an instruction we have to give the model a priori. Once again: the model does not understand what a topic is, so it cannot really identify how many topics there are in a collection of texts. Instead, an LDA model assumes that a writer always chooses the words they use in a text from a predetermined set of topics and it calculates how much a writer used each one of these topics in their text (Doll, 2018).
So if we have to say how many topics there are in a text, how do we know what the best number of topics is? That is the big question. In practice, this is a matter of trial and error. You run your model with for example 10 topics. You then eyeball the sets of keywords it comes up with and try to decide if you need more or fewer topics. Do you see the same theme in multiple sets of keywords? Then you probably need fewer topics for the model to recognize some keywords actually belong together. Do you see some sets of keywords with multiple themes in them? Then you probably need more topics for the model to recognize some keywords actually don’t belong together.
This might sound like a tedious and confusing process. And it is. Choosing the best number of topics is probably what I spend most of my time on while building the model. And you will hardly ever get it perfectly right. But the goal is to strike the best possible balance between coherence within the topics (every set of keywords is about one topic) and diversity between the topics (every set of keywords is about a unique topic).
The output
Once we have built a model we are happy with, we can go ahead and give it our data as input. Depending on the size of our dataset and the computer’s processing speed, it can take a few seconds to a few hours to run the analysis, after which, we get an output that looks something like this:
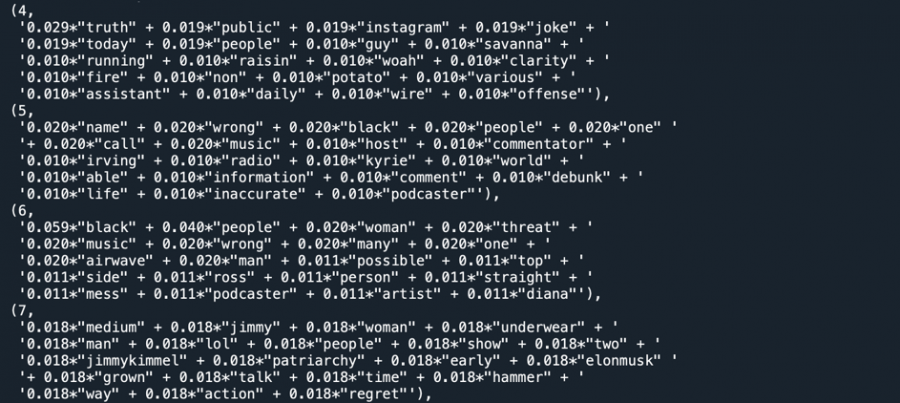
In this screenshot, we see topics 4 – 7. I have asked the model to show the 20 most prominent words in each topic. With that, it gives me a number that represents how much that word contributes to the topic. The higher the number, the more important that word is to the overall topic. Combining the word and the number, we can make a first guess as to what the topics are about. Take a look at topic 6. Here, we find several words that were also in our example retweet (0.059*”black”, 0.020*”woman”, 0.020*”music”, 0.011*”diana”, etc.) And when we go back to our actual data and calculate to which topics the example retweet belongs, we indeed find that it almost perfectly matches topic 6. Now the interesting thing will be to find out what other tweets belong to these topics and to put our ‘old school’ discourse analytical skills in practice to analyze how this topic – let’s call it ‘Black Music’ – is used by Owens to gain attention and spread her metapolitical message in the hybrid media system.
Case study: TLDR
In building an LDA model to identify the topics in tweets by Ben Shapiro and Candace Owens and the replies they received, I had to make a lot of choices. Which parts of speech to include? To lemmatize or not to lemmatize? How many topics are we looking for? At the end of the day, there are no ‘good’ or ‘bad’ choices to make. I made the choices that resulted in the most informative analysis to answer my research questions. That is what counts. LDA topic modeling is a tool, a means to an end rather than an end in itself. And my choices will probably be different in the next project I do. But in every project I undertake, I will have to transform humanly readable data into data that an algorithm can read and perform statistical calculations on. That severely alters the nature of the data, which is why it is important to constantly go back and forward between your original data and your model. You have to make sense of your data – and you can’t leave such an important task to a machine alone. Also, please keep in mind that I’m writing all of this after the fact. In hindsight, everything seems simpler than it is. The process of making data machine-readable and human-readable again might seem straightforward, but in reality, it is messy, confusing, and frustrating – as is all research, I suppose.

The good
So far, we have come to know LDA topic modeling as a pretty messy method of discourse analysis where we have to make a lot of choices before our model actually returns informative results. Still, in some cases, it is worth the trouble. One of the most obvious arguments in favor of LDA topic modeling in discourse analysis is the sheer volume of discourse that can you can analyze. The dataset I used for my project contained around 155.000 tweets and this is still a pretty small dataset for an LDA project. We can follow the same procedure for millions of texts. We can even automate this process to continually analyze the development of topics over time – for example in newspaper articles. My argument here is not that more is always better. But a larger dataset does allow us to engage with our data in different ways, to see trends, patterns, and topics previously not noticed. The L in LDA stands for ‘Latent’. Thus, we can attempt to find things that are ‘hidden’ in the data, but that only manifest themselves once we look at the data from a bird's eye view. We do not have to take these ‘hidden’ trends, patterns, and topics at face value. According to Kirschenbaum (2007), these findings are best interpreted “not as ground truths, but as provocations to ‘close reading’, which can then invite new questions, perspectives and lines of research to the field.”
Using computational methods deepens your understanding of how digital culture works
Another reason why I would recommend everyone to at least try their hand at LDA topic modeling is that I found a deep appreciation for exactly how much human interpretation goes into computational research methods. Before I started my project, I had read about how quantification can have an undeserved air of detached objectivity and truthfulness (e.g. Rasch, 2018; Bucher, 2017). But it was only when I wrote an algorithm myself that I appreciated just how many choices you have to make and how much human interpretation is needed in computational analysis. It is anything but objective or detached. At every point in the LDA topic modeling process, our own knowledge, experiences, biases, and cultural positionality inform our decisions. It is good to understand this when you work with algorithms yourself, but it is just as valuable an insight when you’re reading someone else’s computational analysis. Don’t just take it as truth because they used a computer, or because they analyzed a million texts. Remember there is always a human factor behind the machine.
Finally, of special interest to students of digital culture, using computational methods in your own research deepens your understanding of how digital culture works from a technological point of view. It is easy to forget that all the cultural practices and artifacts we analyze are built on top of digital code. Partly because this code is hidden away behind shiny interfaces, partly because commercial tech companies deliberately obfuscate their code and algorithms from the public (and academic) eye. By learning to write code myself, I felt able to shine a tiny light in the darkness of the black boxes. Google, social media companies, online databases, marketplace platforms, and Chat-GPT all use techniques similar to LDA topic modeling to understand what a text is about. Knowing how these companies and products operate ‘under the hood’ demystifies them and opens them up to our scrutiny.
The bad
LDA topic modeling can help us by provoking new questions, revealing latent patterns, trends, and topics in our data, and developing a deep appreciation for the inner workings of the algorithms that dominate computational research and online culture. But computational discourse analysis also has its downsides. First of all, machines still don’t beat humans when it comes to making meaning out of texts. Our lived, embodied experiences in the social world allow us a keen eye for intertextual, indexical meanings in multimodal discourse. We as humans – and students of culture and society in particular – understand that language is loaded with social and cultural meaning. Not just in what is said, but especially in what is not said (but implied). An algorithm, on the other hand, assumes that language does not hide anything. It takes all data at face value without considering extra layers of meaning. As such, it cannot differentiate between a joke and an earnest comment, a truth and a lie, critical questions, and conspiracy theories, or flirting and sexual harassment.
To acknowledge this is to acknowledge we can't truly call LDA topic modeling a method of discourse analysis. Through the pre-processing and quantification of our rich data (remember the example from earlier), we strip away all layers of context, intertextuality, participants and actions that give the data meaning. From 'language-in-action' we move to language as a transparent collection of countable text units. In other words: we are no longer dealing with discourse. This does not dismiss computational methods as useful tools for discourse analysts, but it does reaffirm the need to remain critical of the affordances of our methods.
The point is to combine the strengths of the human and the machine
That brings me to my last point. Even though the immense volume of data we can analyze with LDA topic modeling allows for new understandings and questions about our data, more is not always better. We should not fall for the theology of Dataism (Brooks, 2013), believing that “data is gold waiting to be mined; that all entities (including people) are best understood as nodes in a network; that things are at their clearest when they are least particular, most interchangeable, most aggregated” (Schulz, 2011). The point, I think, is to combine the strengths of the human and the machine: LDA modeling defines the topics – it's up to us to give meaning to those topics (Templeton, 2011).
Thinking back to the example of the retweet by Candace Owens, topic modeling did not help me to better understand this one tweet, but it did help me to understand this tweet as part of a much larger set of tweets. It allowed me to find that this tweet is actually emblematic of a prevalent topic in Candace Owens' discourse, namely cancel culture in the Afro-American culture industry. Combining this computational birds-eye view of the complete dataset with the granular scrutiny of qualitative discourse analysis of specific tweets results in a more comprehensive understanding of the data at both the micro and the macro level.
In that sense, we can think of LDA topic modeling as a microscope. A microscope offers a different way of looking at the data, which then invites new questions and lines of research. But a microscope without a researcher to interpret what it shows is useless. And just like with the microscope, researchers should be acutely aware of the affordances of computational methods and the way they can obscure insights just as easily as they can reveal them.
Getting started with LDA topic modeling
Fun is an underrated aspect of doing research. Of course, research has to contribute reliable, empirically grounded knowledge to the academic field and society at large. But that does not mean we can’t have fun along the way. And I must admit: I thoroughly enjoyed myself with LDA topic modeling. Learning to code, exploring how algorithms work firsthand, and continuously going back and forward between your data and your code until you finally have those satisfyingly informative topics, and the subsequent feeling of having ‘cracked the code’ is just plain fun.
So for everyone who also wants to try their hand at a new, fun research method that can offer new ways of looking at their data to complement the qualitative research skills that our programs primarily focus on, I want to offer some resources that were helpful for me. First of all, I followed the free tutorial ‘Topic Modeling and Text Classification with Python for the Digital Humanities’ on YouTube to get started with writing my own code. I was already familiar with the basics of Python, but this course really takes you by the hand in teaching you how to write your first TF-IDF and LDA algorithms. Another useful step-by-step tutorial was ‘Topic Modeling with Gensim (Python)’ by Selva Prabhakaran on MachineLearning+. For more information on how to interpret LDA topic modeling results, I can recommend this talk by Matti Lyra. For everyone who wants to get into the nitty-gritty of how topic modeling actually works, the original paper in which Blei, Ng, and Jordan (2003) introduce Latent Dirichlet Allocation is a must. More accessible resources are blog posts by humanities scholars, in particular, ‘Topic Modeling made Just Simple Enough’ and ‘What Kind of “Topics” does Topic Modeling Actually Produce’ by Ted Underwood and ‘Topic Modeling in the Humanities: an Overview’ by Clay Templeton. Are you not interested in how topic modeling works, but do you still want to reap the benefits of this method, even if it’s just for a try? Then you should look into MALLET, which saves you a lot of programming and statistics hassle. The tutorial ‘Getting Started With Topic Modeling and MALLET’ should give you a great introduction.
Finally, all the referenced literature in this article is worth a read. I hope it will encourage you to try something new. And to have some fun.
References
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022.
Doll, T. (2019, March 11). LDA Topic Modeling. Medium.
Kirschenbaum, M. (2007). The Remaking of Reading: Data Mining and the Digital Humanities.
SpaCy. (n.d.). Linguistic Features · spaCy Usage Documentation. Linguistic Features.
Templeton, C. (2011, August 1). Topic Modeling in the Humanities: An Overview. MITH.
Underwood, T. (2012b, April 7). Topic modeling made just simple enough. The Stone and the Shell.
Venturini, T. (2019). From Fake to Junk News, the Data Politics of Online Virality. In D. Bigo, E. Isin, & E. Ruppert (Eds.), Data Politics: Worlds, Subjects, Rights. London: Routledge (forthcoming).